New Strategic USZ RDF Pipeline using SPHN Connector
Note
The following documentation about implementation is provided by Universitätsspital Zürich (USZ). For additional information or questions, please send an email to SPHN Data Coordination Center at dcc@sib.swiss.
Overview
In order to use the SPHN Connector and ingest data to be transformed to RDF, various integration steps are necessary. The following graph gives you an overview of the overall process to generate RDF files that can be sent to the projects or in the future to the Core Data Repository.
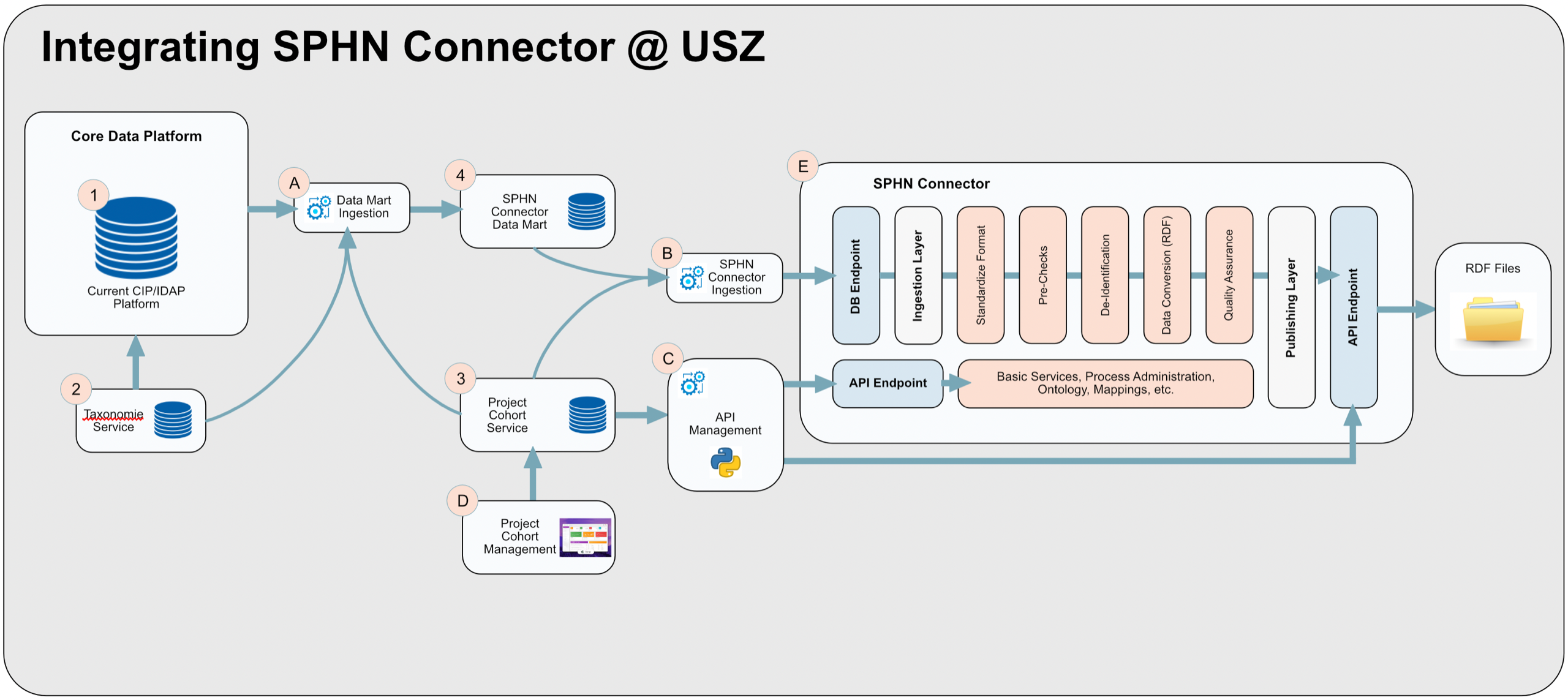
The graph shows various data storage/sources that are necessary and these are numbered. The ETL processes are labeled by alphabet. An functional overview of these steps is described below.
As this pipeline is in development, including the SPHN Connector by SPHN, details of the implementation might change.
Foreseen Technologies are:
MS-SQLfor the data storage outside the SPHN ConnectorPostresis the database in the SPHN Connector where the data is copied into from the Trusted Research Data MartT-SQLis used within the Core Data Platform and to populate the Trusted Research Data Mart.Python/Djangois used to provide the functionality to control and manage the SPHN Connector and managing the project cohort definition
Definition of Projects
There are two kinds of projects in the context of the SPHN Connector and the Research Architecture:
Research Projects- These are the common projects as e.g. the SPHN PSSS, Frailty, SPO etc. but also the NDS and Demonstrator projects where USZ delivers data in RDF format.Research Pipeline- This project covers the whole research architecture and is based on one trusted research data mart and core data repository that contains all our data that is available to research in standardized and coded way without data duplication. This will in the long term replace all the individual Research Projects, which will get their data from the Core Data Repository via specific Service Connector.
Data storage/sources
1. Core Data Platform (CDP)
The source of all primary data that is available for secondary use
Until we have implemented our new Core Data Platform (CDP) the source for all the data comes from the current CIP/IDAP data platform. The codes used in the CDP correspond mostly to local codes except where the source systems implements standards (e.g. LOINC in MOLIS) or in cases where the import already applies mappings to global standards.
For the purpose of the SPHN Connector we assume that all data required is already integrated into the CDP and is available for extraction for the SPHN Connector. Missing data in the CDP would be integrated by a given project that requests this data.
2. Taxonomie/Terminology Service (TS)
Provides mapping functionalities to map internal codes to standardized terms provided by taxonomies
The data in the SPHN Connector Data Mart should be aligned to concepts defined by SPHN, LOOP and other research projects. This means that all the mapping should be done before the data is loaded into the Trusted Research Data Mart (TRDM). The Taxonomie Service is foreseen to be Ontocat or any corresponding replacement with the new data platform and needs to provide mappings from the source values to the values defined in the ontologies (SPHN, LOOP and projects).
In an interim solution this could also be just some SQL tables that provide source/target mapping for given codes.
The target codes should include all possible values from taxonomies defined by SPHN (Snomed CT, LOINC, ATC, ICD-10 GM, CHOP, UCUM) but also all individuals defined in the SPHN and project ontologies used to define the value sets.
3. Project Cohort Service (PCS)
Defines the data that needs to be transmitted for a project or the project is allowed to access
The Project Cohort Service (PCS) specifies which data will be loaded into the TRDM for a given project but also which project has access/requested which data. The PCS manages the following dimension:
Project
Patients
Concepts
Which data for a given Concept, i.e. which lab codes or which substances for Drug Prescriptions/Drug Administration.
Time span
The project “Research Pipeline” should contain all the data that is used for all the projects plus all the data that will be available for research in the Core Data Repository (CDR)(not depicted above) that is not yet used in a project.
4. Trusted Research Data Mart (TRDM)
Stores all data that is available for research in a standardized, high quality and ontology based form ready to be ingested into the SPHN Connector
The TRDM is project independent, respectively is based on the project type “Research Pipeline” (see “Project Definitions”). This means all data for a given patient is only stored once. Data that needs to be ingested into the SPHN Connector for a given project, will be extracted from the TRDM using the PCS in order to select the specific set of data.
The structure of the data mart should be based/aligned to the ontologies that are used to describe the data and the data is de-identified.
Processes/Functions
Integrating source data into the SPHN Connector Data Mart
ETL pipeline that transforms and copies data from the CDP into the TRDM while mapping codes and de-identifying the data
This ETL process is setup in a streaming or periodic frequency mode and will copy patients or their data once they fulfill a trigger requirement. The ETL process will make sure that all codes that are not yet mapped to the standard taxonomies at source or while loading into the CDP are mapped to the SPHN and project specific value sets. Additionally it will de-identify the data by replacing patient and administrative case ids with pseudonyms as well as shift the dates. Finally the data is translated into the structure as defined in the TRDM which is aligned to the data base structure as setup in the postgres database in the SPHN Connector.
Note: with the new clinical data platform this process needs to be replaced with the new technologies and taking the data from the new CDP.
Ingest data from the Trusted Research Data Mart into the SPHN Connector
ETL pipeline that copies the data from the TRDM into the SPHN Connector based on project definition in the project cohort service
This ETL process is setup in a streaming or periodic frequencey mode and will copy patients or their data to the SPHN Connector postgres database once they fulfill a trigger requirement. The selection of the data that needs to be ingested into the SPHN Connector is project based and is defined in the PCS. If a patient is to be transferred, all data for this patient needs to be re-ingested, even if there is only one new instance of data like e.g. a new body temperature measurement.
SPHN Connector API Management
A command and control app that allows to setup projects, up-/download files, start processes and monitor the SPHN Connector status
The API Management app will call the various API endpoints of the SPHN Connector which are the following groups:
Create project and upload ontology, taxonomy and sparQL queries as well as optional Shacl files and at the end initialize the project.
After the project initialization the log files should be checked to make sure the initialization was executed correctly.
Optionally it should be able to download the DDL statements from the postgres database creation.
Manage project definitions by resetting a project (deleting data) or deleting a project completely.
Optionally it should be possible to ingest RDF files for validation purpose only
Start and stop the pipeline
Retrieve log files and analyise them for correct execution
Download RDF files
Optionally create new users and manage their passwords
Optionally upload and download de-identification rules and activate/de-activate de-identification
Optionally upload pre-check conditions
Additionally it should alert users in case some process have errors or RDF files have errors in the QC validation.
It is also helpful to coordinate the project definition with the PCS/PCM in order that a project only needs to be setup once.
Pre-requisites: The SPHN Connector needs to be setup correctly and login credentials for the API Management tool is defined in the SPHN Connector.
Project Cohort Management (PCM)
A web client that easily allows the definition of the dimension of a project cohort
The PCM allows to capture the criteria that define the project cohort (see Project Cohort Definition) in a web client. This setup needs to be done prior to any data be ingested into the SPHN Connector and it must match the definition on the project study document as applied in the data governance board and approved by the ethics commitee.
SPHN Connector
ETL Tool that transforms data from tabular or JSON format into validated RDF data according to SPHN specification
The SPHN Connector is developed and provided by SPHN. The SPHN Connector provides two types of API end-points to communicate with:
Database- used to ingest data into the postgres database that is part of the SPHN Connector.API- used to manage (command and control) the processes but also to ingest JSON or RDF files and retrieve the validated RDF files.