SPHN Connector
Note
> Watch the SPHN Webinar introducing the SPHN Connector
Introduction
Data Providers in the SPHN network use a variety of database systems to store their clinical data, which can be found in diverse formats such as a structured SQL database or in different structured formats. Validating data quality is difficult to manage with large amounts of data, and is sometimes regarded as time-consuming and resource-intensive, delaying the work that researchers need to achieve.
The SPHN Connector is a containerized solution that allows data-providing institutions to build a pipeline that converts their data from relational or JSON sources into graph data based on a RDF schema conforming to the SPHN Framework. The ingested data is converted into RDF and validated to check its conformity with the schema. Optionally, data providers that do not have an in-house de-identification functionality, can activate the module for de-identification in the SPHN Connector.
The SPHN Connector integrates a variety of tools developed or distributed by SPHN like the SHACLer or the SPHN RDF Quality Check Tool to simplify the production of high quality data. In the context of SPHN, the SPHN Connector is intended to and can be used by any data provider for an easier creation and validation of data in RDF.
The SPHN Connector is built with flexibility and simplicity in mind. It requires only two inputs: The patient-level data and the base schema which can be the SPHN RDF Schema and optionally a project-specific RDF Schema.
Almost everything else can be adapted by the user to fit its needs and skills, and the working environment. One example is the variety of input data that is supported by the SPHN Connector: a user can upload JSON files, RDF files or setup a specific database import. The user also has the option to configure validation parameters. Experienced users can provide their own SHACL file for validation, while others can simply use the file that is created by the SPHN Connector via the SHACLer.
The SPHN Connector provides the user with an entire pipeline for creating and validating patient data using Semantic Web technologies.
Overview, architecture & workflow
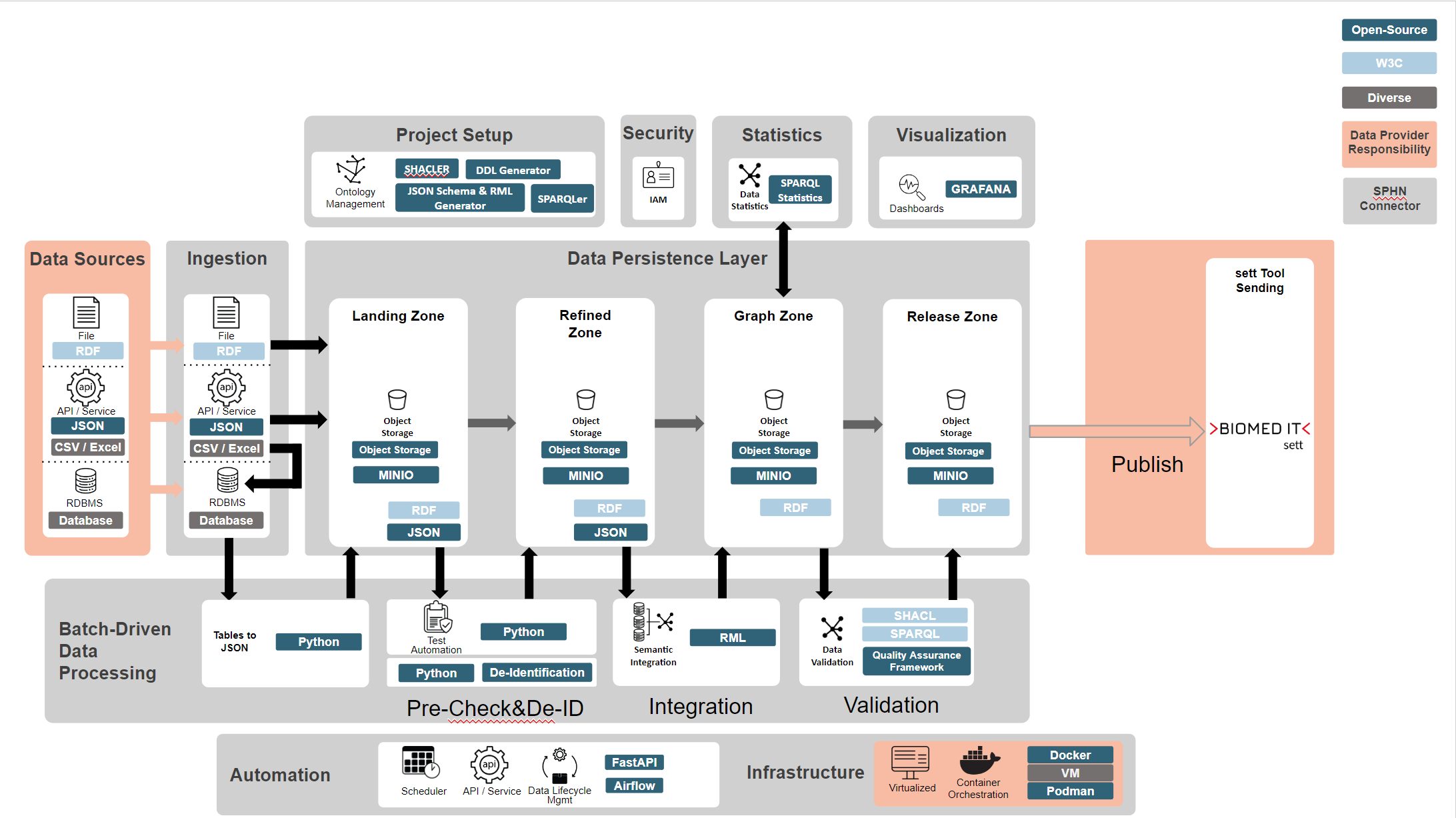
Figure 1. Core elements of the SPHN Connector architecture.
As seen in the picture the process of creating and validating the data follows 4 steps:
- 1) Ingestion
While not being an official phase of the SPHN Connector the ingestion phase sets the environment for the further processing of the data. To be able to analyze and transform medial data a users sets up a project in the SPHN Connector. A project bundles dependencies that are latter used e. g. for validating the imported data. Data provided by the user is imported into the MinIO object storage of the SPHN Connector, following a suitable formatting process. As a first step the user adds the SPHN schema and optionally a project related schema to the Connector. In a second step the necessary terminologies files are added to the Connector. Finally the medical data can be ingested into the project. There are multiple options to ingested data into the SPHN Connector. For further information see the section ‘Multiple import formats’ below.
- 2) Pre-Check & De-Identification
To ensure that the input data is valid, in an expected format, and RDF data can be produced from the data, pre-checks can be either defined or the default ones used. By the default the SPHN Connector checks for spaces and special characters in French & German to avoid them later on during the IRI creation. These default checks are limited to the id fields of the JSON file but a user can define them for any field as needed. It is possible to define checks that only verify the input data while others will directly alter the input data (replace checks). If a user has no means of de-identification, the SPHN Connector can be configured to take care of this step.
- 3) Integration
During the Integration phase, the patient-based JSON data is mapped to RDF via the RMLmapper, resulting in one RDF file per patient. This step is necessary to use later the validation from the SHACLer in the SPHN RDF Quality Check Tool.
- 4) Validation
During the Validation phase, the RDF data is checked against SHACL shapes (see: Shapes Contraint Language (SHACL) ) generated by the SHACLer based on the provided ontologies plus additionally, manually provided SPARQL queries. The resulting validation report states if the patient data complies to the provided semantic definitions and is categorized as valid or not. The user can evaluate the output via different logging endpoints provided by the SPHN Connector.
- 5) Optional: Statistics
As an optional last phase the SPHN Connector supports since version 1.3.0 the extraction of statistical data from the ingestion patient data. To generate statistical data the SPHN SPARQL Queries Generator is used to create SPARQL queries that covers concepts present in the SPHN RDF Schema. The results are gathered and can be extracted afterwards via the SPHN Connector API as a report. In general two modes are available: “fast” and “extensive”. If the statistics are executed in the “fast” mode the computation is fast while the output not as fine granular as it may be needed. The “extensive” modes offers a detailed view into the patient’s data with the downside of being computational expensive and thus, slow.
Distinguished features of the SPHN Connector
Besides the functionalities listed above, the SPHN Connector supports the user further with respect to the data ingestion and handling of PII (Personal Identifiable Information).
- User centric ingestion options
While the options for importing the relevant schema(s) and terminologies are strictly limited to a RDF format the options for importing data into the SPHN Connector are more flexible. To be able to smoothly integrate the SPHN Connector in the users’ IT landscape a variety of data formats are supported: RDF (.ttl), JSON, database import, Excel workbooks and CSV files can be used. Due to the heterogeneity of those input types, the processing steps differ between the file formats. Furthermore, some file formats support batch ingestion (RDF & JSON) which increases the ingestion time drastically. Figure 2 gives an overview of the different ingestion formats and methods.
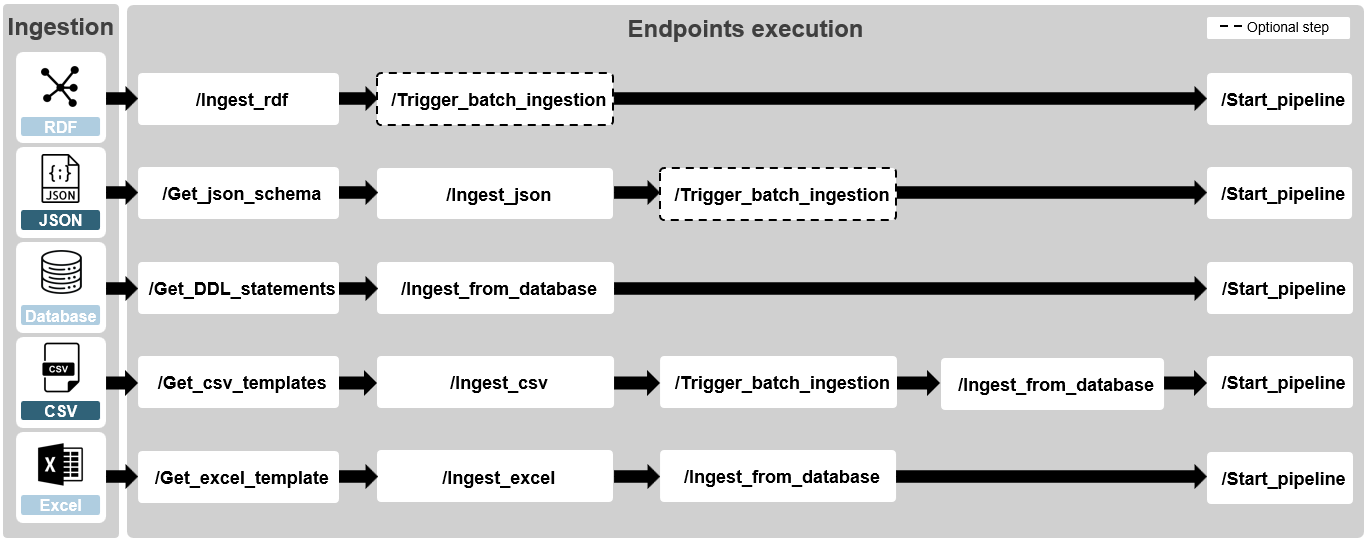
Figure 2. Ingestion methods and steps for the SPHN Connector.
- Handling PII with de-identification capabilities
As mentioned above, the SPHN Connector offers a De-Identification capability for users that do not have the means to deploy their own solutions. The de-identification configuration can be uploaded by the users after a successful project creation and should, in a minimal configuration, include the SubjectPseudoIdentifier, AdministrativeCase, and Sample as well as a date-shift to ensure that the most critical PII is taken care of. The SPHN Connector keeps track of updates and changes applied to the data. Therefore, it is possible for an admin user to apply the exact same changes to future data sent for the same patient. Meaning, no inconsistency is introduced to the data while information security is uphold.
SPHN tools used in SPHN Connector
The following SPHN tools are used in the SPHN Connector:
SPHN RDF Quality Check Tool
The SPHN RDF Quality Check tool (also referred as “QC tool”) is a Java-based tool that facilitates the validation of data in compliance with the SPHN RDF Schema or a SPHN project-specific schema.
The QC tool is primarily intended for Data Providers to use for checking their data prior to sending it to Data Users or Projects. Although it is now integrated in the SPHN Connector, it can be used as a standalone tool by anyone who wants to check their data against the SPHN or a project-specific RDF Schema.
One major advantage of the QC tool is that there are no transaction size limits: bulk uploads can be in hundreds of millions of triples, depending on the machine’s resources. The QC tool generates a report that displays errors in tables which can be exported as flat files per concept as CSV, TSV, JSON or XML. More details are available in the README.md.
Note
For more information about the QC tool hardware requirements and dependencies, please read the README.md
The QC tool currently supports the following operations:
Checking compliance of data with the RDF schema and the SHACL constraints of the project
Quantitative profiling of the data for evaluating its completeness with pre-defined SPARQL queries
Data validation with SHACL
SHACL rules generated by the SHACLer tool are integrated in the SPHN Connector to validate the compliance of the RDF data produced with the SPHN RDF Schema using the QC tool.
Integrated SHACLs are described in SHACL constraint components implemented in SPHN.
Availability and usage rights
© Copyright 2026, Personalized Health Informatics Group (PHI), SIB Swiss Institute of Bioinformatics.
The SPHN Connector is available on Git.
It is licensed under the GPLv3 License.
Its installation is explained in a 7 minutes SPHN Connector installation guide video.
The SPHN Quality Check tool is co-developed by SIB Swiss Institute of Bioinformatics and HUG members.
It is available on Git.
and is licensed under the GPLv3 License.
For any question or comment, please contact the SPHN FAIR Data Team at fair-data-team@sib.swiss.
Further reading
Touré, V., Unni, D., Krauss, P., Kalt, K., Stoira, N., Pickl, M., Österle, S. (2025). SPHN Connector - A scalable pipeline for generating validated knowledge graphs from federated and semantically enriched health data, Research Square (preprint). (https://doi.org/10.21203/rs.3.rs-7930982/v1)