Resource Description Framework (RDF)
Introduction to RDF
The Resource Description Framework (RDF, https://www.w3.org/RDF/) is a standard for the exchange of information on the Web. RDF is based on a graph data model where data are represented in the form of triples. A triple consists of two nodes connected by an edge [1]. The power of RDF lies in the fact that a RDF statement expresses a relationship between two nodes, i.e. two resources: A subject and an object represent the two nodes being related, while the predicate represents the nature of their relationship [2]. RDF data are thus directed, labeled graphs. In RDF, anything can be connected simply by drawing a line [3]. It is in this way that “RDF enables effective data integration from multiple sources, detaching data from its schema. This allows multiple schemas to be applied, interlinked, queried as one and modified without changing the data instances” [4].
Data Representation with Triples
Knowledge in RDF is expressed as a list of statements, roughly following the structure of a sentence in a natural language. A RDF statement consists of a subject (node), a property (edge), and an object (node). This subject-property-object combination forms a “triple”.
For example, we can express the sentence “A patient has a healthcare provider which is the University Hospital Basel.”
as a triple having the nodes <https://biomedit.ch/rdf/sphn-resource/patient> and <https://biomedit.ch/rdf/sphn-schema/sphn#UniversityHospitalBasel>
connected by an edge of type <https://biomedit.ch/rdf/sphn-schema/sphn#hasDataProvider>.
Similarly, we can express the sentence “The University Hospital Basel is a healthcare provider “
by connecting the <https://biomedit.ch/rdf/sphn-schema/sphn#UniversityHospitalBasel>
node to the <https://biomedit.ch/rdf/sphn-schema/sphn#DataProvider>
node through the rdf:type property.
Note
The subject in the last example is the object in the first example,
resulting in a path from <https://biomedit.ch/rdf/sphn-resource/patient>
to the <https://biomedit.ch/rdf/sphn-schema/sphn#hasDataProvider>,
as shown in the textual and visual representation below.
<https://biomedit.ch/rdf/sphn-resource/patient> <https://biomedit.ch/rdf/sphn-schema/sphn#hasDataProvider> <https://biomedit.ch/rdf/sphn-schema/sphn#UniversityHospitalBasel> .
<https://biomedit.ch/rdf/sphn-schema/sphn#UniversityHospitalBasel> a <https://biomedit.ch/rdf/sphn-schema/sphn#DataProvider> .
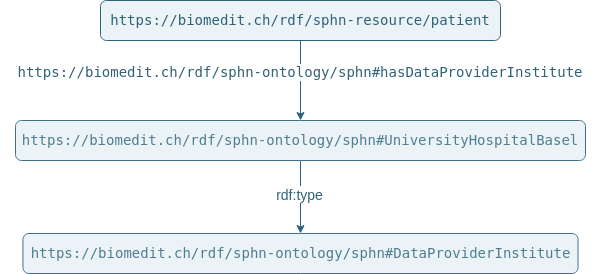
Figure 1: Visual representation of an example of an RDF triple.
RDF Terms
A RDF graph is a collection of triples.
A node in a RDF graph can be one of the following kind [5]:
Uniform Resource Identifier (URI), or more broadly speaking Internationalized Resource Identifier (IRI), is used to uniquely identify and reference resources. An URI is a subset of an IRI, and as such, an IRI is more generic. URIs are universal and consistent across databases, and do not need to be resolvable (i.e. browsable on the web). Here is an example of an URI:
<https://biomedit.ch/rdf/sphn-resource/patient>
Literal data values, which are character strings by default (e.g. “University Hospital Basel”). Literals have specific datatypes: “RDF reuses the same datatypes that XML uses, including xsd:string, xsd:float, xsd:double, xsd:integer, and xsd:date, as well as custom datatypes that are named after an URI.” [6]. Additionally, literal data values can also be language-tagged. Here is an example using the CHOP coding system where language labels (German, French and Italian) are added to literal values.
chop:C1 a rdfs:Class ;
rdfs:label "Operationen am Nervensystem (01–05)"@de,
"Opérations du système nerveux (01–05)"@fr,
"Interventi sul sistema nervoso (01-05)"@it ;
Note
A node can also be of kind “blank node”, which can be summarized as a resource without a URI. It is an identifier that is only valid inside a given data file, and typically a blank node cannot be queried by itself. In the context of SPHN, blank nodes are not used to refer to SPHN elements. Further information on blank nodes can be found here.
The subject and property of a RDF triple must be an URI/IRI, while an object can either be an URI/IRI or a literal value [3].
RDF Storage Formats
RDF content can be represented in various formats (e.g. OWL, XML, Turtle, N-Triples). The textual examples given above come from the Turtle format, in which URIs are written within angle brackets (< >), literals in quotation marks (“ “), and triple usually ending with a period (.). The Turtle format (Terse RDF Triple Language) is a simple and easy way to parse RDF and is more concise and readable compared to N-Triples.
Turtle Prefix
With Turtle, which has as extension .ttl [6],
one can define a namespace prefix so that any relative URI in the Turtle file does not have to be repeated resulting in a lengthy and verbose data file.
A prefix definition, found at the beginning of a .ttl file, looks like the following:
@prefix pref: <uri prefix > .
For example, for SPHN elements, the following prefix is defined:
@prefix sphn: <https://biomedit.ch/rdf/sphn-schema/sphn#> .
Now, when referring to the UniversityHospitalBasel element, instead of spelling out the entire URI <https://biomedit.ch/rdf/sphn-schema/sphn#/UniversityHospitalBasel>,
we can simply use the predefined sphn prefix in its place. The following two examples carry the same information, but the second notation is more human-readable
<https://biomedit.ch/rdf/sphn-schema/sphn#UniversityHospitalBasel> rdf:type <https://biomedit.ch/rdf/sphn-schema/sphn#DataProvider> .
@prefix sphn: <https://biomedit.ch/rdf/sphn-schema/sphn#> .
sphn:UniversityHospitalBasel rdf:type sphn:DataProvider .
Turtle Notations
Period
As seen in the examples above, a triple statement is always concluded with a period in a Turtle file.
Semicolon
Turtle enables one to complement information about the same subject through the use of a semicolon.
The following two examples carry the same information, but the second notation is more concise thanks to the use of the semicolon which avoids the repetition of the subject, sphn:UniversityHospitalBasel:
@prefix sphn: <https://biomedit.ch/rdf/sphn-schema/sphn#> .
@prefix resource: <https://biomedit.ch/rdf/sphn-resource/> .
sphn:UniversityHospitalBasel rdf:type sphn:DataProvider .
sphn:UniversityHospitalBasel sphn:hasCode resource:Code-UID-CHE-306_012_948 .
@prefix sphn: <https://biomedit.ch/rdf/sphn-schema/sphn#> .
@prefix resource: <https://biomedit.ch/rdf/sphn-resource/> .
sphn:UniversityHospitalBasel rdf:type sphn:DataProvider ;
sphn:hasCode resource:Code-UID-CHE-306_012_948 .
Comma
Similarly, one can complement information about the same subject-object combination through the use of a comma as shown in the CHOP example below where multiple labels are provided in different languages for the CHOP class C1.
chop:C1 a rdfs:Class ;
rdfs:label "Operationen am Nervensystem (01–05)"@de,
"Opérations du système nerveux (01–05)"@fr,
"Interventi sul sistema nervoso (01-05)"@it ;
rdf:type vs a
Turtle also allows a shortcut for its rdf:type property by way of using a. Adding the prefixes, the above example can be written rewritten as follows:
@prefix sphn: <https://biomedit.ch/rdf/sphn-schema/sphn#> .
@prefix resource: <https://biomedit.ch/rdf/sphn-resource/> .
sphn:UniversityHospitalBasel
a sphn:DataProvider ;
sphn:hasCode resource:Code-UID-CHE-306_012_948 .